阿里通义千问重磅开源Qwen2.5-Omni:新一代端到端多模态大模型
3月27日,阿里云通义千问Qwen团队正式发布Qwen模型家族新一代端到端多模态旗舰模型——Qwen2.5-Omni。该模型专为全方位多模态感知设计,可无缝处理文本、图像、音频和视频等多种输入模态,并支持实时流式生成文本与自然语音合成输出。
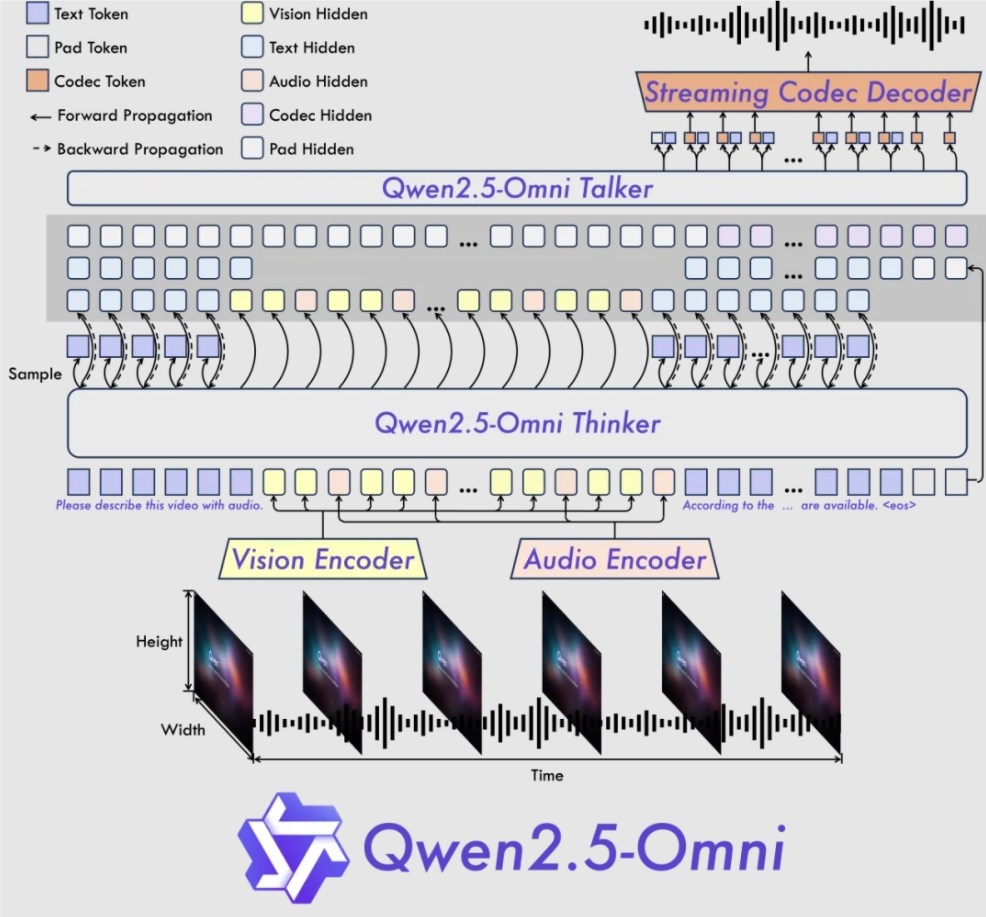
技术架构方面,Qwen2.5-Omni采用创新的Thinker-Talker架构:
- Thinker模块:作为"大脑",负责多模态输入处理和高层语义表征生成
- Talker模块:作为"发声器官",实时接收语义表征并流畅合成离散语音单元
- 创新技术:提出TMRoPE(Time-aligned Multimodal RoPE)位置编码技术,通过时间轴对齐实现音视频输入的精准同步
核心性能优势:
- 实时交互:支持分块输入和即时输出,实现完全实时的音视频交互
- 语音质量:在自然性和稳定性方面超越现有流式/非流式方案
- 全模态表现:在同等规模单模态模型基准测试中展现卓越性能
- 音频能力优于Qwen2-Audio
- 视觉能力与Qwen2.5-VL-7B持平
- 指令跟随:端到端语音指令处理效果媲美文本输入
- 基准测试:在MMLU通用知识理解、GSM8K数学推理等测试中表现优异
性能对比:
-
多模态表现:
- 全面超越同类单模态模型(Qwen2.5-VL-7B、Qwen2-Audio)
- 优于封闭源模型(如Gemini-1.5-pro)
- 在OmniBench多模态任务中达到SOTA水平
-
单模态表现:
- 语音识别(Common Voice)
- 翻译(CoVoST2)
- 音频理解(MMAU)
- 图像推理(MMMU、MMStar)
- 视频理解(MVBench)
- 语音生成(Seed-tts-eval及主观听感评估)
开放生态:
模型已在Hugging Face、ModelScope、DashScope和GitHub开源,用户可通过:
- Demo体验互动功能
- Qwen Chat进行语音/视频聊天
沉浸式体验Qwen2.5-Omni的强大性能
Qwen Chat:https://chat.qwenlm.ai
Hugging Face:https://huggingface.co/Qwen/Qwen2.5-Omni-7B
ModelScope:https://modelscope.cn/models/Qwen/Qwen2.5-Omni-7B
DashScope:https://help.aliyun.com/zh/model-studio/user-guide/qwen-omni